Web scraping при помощи node.js
Содержание:
- Playwright: Chromium, Firefox and Webkit browser automation#
- PromptCloud
- Web Harvey
- Сервисы для веб-скрапинга
- StormCrawler
- Извлечение данных с сайта через Scrapy
- How to Select a Web Scraping Tool?
- The basics of web scraping
- WebDrivers and browsers
- How do Web Scrapers Work?
- The basics of web scraping
- Инструменты
- Scraping multiple pages
- Парсинг
- Scrapehero
- The Best Web Scraper
- Обратная разработка
- Интеграция облачного сервиса
- Вывод
- Octoparse
- Создание tasks.py с помощью Celery
Playwright: Chromium, Firefox and Webkit browser automation#
Playwright can be considered as an extended Puppeteer, as it allows using more browser types (Chromium, Firefox, and Webkit) to automate modern web app testing and scraping. You can use Playwright API in JavaScript & TypeScript, Python, C# and, Java. And it’s excellent, as the original Playwright maintainers support Python.
The API is almost the same as for Pyppeteer, but have sync and async version both.
Installation is simple as always:
pip install playwright
playwright install
Copy
Let’s rewrite the previous example using Playwright.
from bs4 import BeautifulSoup
from playwright.sync_api import sync_playwright
import os
with sync_playwright()as p
browser = p.chromium.launch()
page = browser.new_page()
page_path =»file://»+ os.getcwd()+»/test.html»
page.goto(page_path)
page_content = page.content()
soup = BeautifulSoup(page_content)
print(soup.find(id=»test»).get_text())
browser.close()
Copy
As a good tradition, we can observe our beloved output:
I ️ ScrapingAnt
Copy
We’ve gone through several different data extraction methods with Python, but is there any more straightforward way to implement this job? How can we scale our solution and scrape data with several threads?
Meet the web scraping API!
PromptCloud
|
Try PromptCloud |
Tackling complex and challenging assignments |
If you are looking for a web scraping service that is enterprise-grade and yet fully managed, setting you absolutely free to focus on your business, PromptCloud fits the description. Yes, PromptCloud is a market leader in web scraping for a variety of reasons.
With this service, you are likely to just sit back and relax because it will take care of everything. From building and maintaining a scraper to ensuring data quality to data delivery, it just excels at every part of the process.
It doesn’t matter how complex is your task or requirement, PromptCloud specializes in tackling the complex and challenging web scraping assignments and creating customized data feeds for your specific needs. A sophisticated monitoring system keeps track of the slightest website changes so that you don’t miss out on even a single piece of data.
Add to the complexity, the requirement of quantity or scalability, and yet PromptCloud comes out on top.
PromptCloud is also absolutely flexible, ready to serve you in whichever way possible. Whether it’s the data source, data frequency, or anything else, it’s always willing to make the changes and serve you better. We have devised the data-aggregation feature of our web-crawler which enables clients to get data from multiple sources in a single stream. This feature can be a great asset for you- whether you are a news aggregator or job boards. Whether you need them to clean the data or provide the different supporting formats for the clean data, they do it all with a smile!
With an army of data wizards at their disposal, they attend to the minutest of details and deliver best-in-class web scraping service to tens of thousands of clients worldwide.
With a slew of stunning service features, it’s no wonder why PromptCloud ranks with the other competitors on our list of top 10 web scraping services!
Promptcloud’s Pricing
- Promptcloud offers monthly pricing.
- The monthly bill is calculated based on the crawling frequency and data volume.
- Scrape 10,000 records for $5
- Site maintenance & monitoring fee ⇒ $79
- Eg: If we are crawling a site every week and deliver, say, 50,000 records in a month, the cost for this site on the monthly bill would be: $15 (for volume fee) + $79 (towards site maintenance & monitoring fee) = $94 for the month.
Web Harvey
WebHarvey’s visual web scraper has an inbuilt browser that allows you to scrape data such as from web pages. It has a point to click interface which makes selecting elements easy. The advantage of this scraper is that you do not have to create any code. The data can be saved into CSV, JSON, XML files. It can also be stored in a SQL database. WebHarvey has a multi-level category scraping feature that can follow each level of category links and scrape data from listing pages.
The website scraping tool allows you to use regular expressions, offering more flexibility. You can set up proxy servers that will allow you to maintain a level of anonymity, by hiding your IP, while extracting data from websites.
Сервисы для веб-скрапинга
Скрапинг требует правильного парсинга исходного кода страницы, рендеринга JavaScript, преобразования данных в читаемый вид и, по необходимости, фильтрации… Звучит суперсложно, правда? Но не волнуйтесь — есть множество готовых решений и сервисов, которые упрощают процесс скрапинга.
Вот 7 лучших инструментов для парсинга сайтов, которые хорошо справляются с этой задачей.
1. Octoparse
Octoparse — это простой в использовании скрапер для программистов и не только.
Цена: бесплатен для простых проектов, но есть и платные тарифы: 75 $ в месяц — стандартный, 209 $ — профессиональный.
Особенности:
- Работает на всех сайтах: с бесконечным скроллом, пагинацией, авторизацией, выпадающими меню и так далее.
- Сохраняет данные в Excel, CSV, JSON, API.
- Данные хранятся в облаке.
- Скрапинг по расписанию или в реальном времени.
- Автоматическая смена IP для обхода блокировок.
- Блокировка рекламы для ускорения загрузки и уменьшения количества HTTP запросов.
- Можно использовать XPath и регулярные выражения.
- Поддержка Windows и macOS.
2. ScrapingBee
Сервис ScrapingBee Api использует «безлоговый браузер» и смену прокси. Также имеет API для скрапинга результатов поиска Google.
Цена: бесплатен до 1 000 вызовов API, после чего нужно выбрать платный тариф от 29 $ в месяц.
Особенности:
- Рендеринг JS.
- Ротация прокси.
- Можно использовать с Google Sheets и браузером Chrome.
3. ScrapingBot
ScrapingBot предоставляет несколько API: API для сырого HTML, API для сайтов розничной торговли, API для скрапинга сайтов недвижимости.
Цена: бесплатный тариф на 100 кредитов и платные тарифы: 47 $ в месяц для фрилансеров, 120 $ в месяц для стартапов и 361 $ в месяц для бизнеса.
Особенности:
- Рендеринг JS (безголовый Chrome).
- Качественный прокси.
- До 20 одновременных запросов.
- Геотэги.
- Аддон Prestashop, интегрирующийся на ваш сайт для мониторинга цен конкурентов.
4. Scrapestack
Scrapestack — это REST API для скрапинга веб-сайтов в реальном времени. Он позволяет собирать данные с сайтов за миллисекунды, используя миллионы прокси и обходя капчу.
Цена: бесплатный тариф до 1 000 запросов и платные тарифы от 19,99 $ в месяц.
Особенности:
- Одновременные API запросы.
- Рендеринг JS.
- Шифрование HTTPS.
- Более 100 геолокаций.
5. Scraper API
Scraper API работает с прокси, браузерами и капчей. Его легко интегрировать — нужно только отправить GET запрос к API с вашим API ключом и URL.
Цена: 1000 вызовов API бесплатно, тариф для хобби — 29 $ в месяц, для стартапов — 99 $ в месяц.
Особенности:
- Рендеринг JS.
- Геотэги.
- Пул мобильных прокси для скрапинга цен, результатов поиска, мониторинга соцсетей и так далее.
6. ParseHub
ParseHub — ещё один сервис для веб-скрапинга, не требующий навыков программирования.
Цена: бесплатный тариф, стандартный тариф — 149 $ в месяц.
Особенности:
- Понятный графический интерфейс.
- Экспорт данных в Excel, CSV, JSON или доступ через API.
- XPath, регулярные выражения, CSS селекторы.
7. Xtract.io
Xtract.io — это гибкая платформа, использующая технологии AI, ML и NLP.
Её можно настроить для скрапинга и структурирования данных сайтов, постов в соцсетях, PDF-файлов, текстовых документов и электронной почты.
Цена: есть демо-версия
Особенности:
- Скрапинг данных из каталогов, финансовых данных, данных об аренде, геолокационных данных, данных о компаниях и контактных данных, обзоров и рейтингов.
- Преднастроенная система для автоматизации всего процесса извлечения данных.
- Очистка и валидация данных по заданным правилам.
- Экспорт в JSON, текст, HTML, CSV, TSV.
- Ротация прокси и прохождение капчи для скрапинга данных в реальном времени.
⌘⌘⌘
Независимо от того, чем вы занимаетесь, парсинг веб-страниц может помочь вашему бизнесу. Например, собирать информацию о своих клиентах, конкурентах и прорабатывать маркетинговую стратегию.
StormCrawler
StormCrawler is a library and collection of resources that developers can leverage to build their own crawlers. The framework is based on the stream processing framework Apache Storm and all operations occur at the same time such as – URLs being fetched, parsed, and indexed constantly – which makes the whole crawling process more efficient.
It comes with modules for commonly used projects such as Apache Solr, Elasticsearch, MySQL, or Apache Tika and has a range of extensible functionalities to do data extraction with XPath, sitemaps, URL filtering or language identification.
Requirements – Apache Maven, Java 7
Available Selectors – XPath
Available Data Formats – JSON, CSV, XML
Pros
- Appropriate for large scale recursive crawls
- Suitable for Low latency web crawling
Cons
Does not support document deduplication
Извлечение данных с сайта через Scrapy
Scrapy по умолчанию не выполняет Javascript код. По этой причине при попытке сделать скрапинг на сайте, что использует Javascript-фреймворки вроде Angular или React.js, у вас могут возникнуть проблемы с получением доступа к запрашиваемым данным.
Попробуем использовать некоторые XPath выражения для извлечения названия и цены продукта:
Для извлечения цены мы используем выражение XPath, выберем первый после с классом
Shell
In : response.xpath(«//div/span/text()»).get()
Out: ‘20.00$’
|
1 2 |
In16response.xpath(«//div/span/text()»).get() Out16’20.00$’ |
Я мог также использовать следующий CSS селектор:
Shell
In : response.css(‘.my-4 span::text’).get()
Out: ‘20.00$’
|
1 2 |
In21response.css(‘.my-4 span::text’).get() Out21’20.00$’ |
How to Select a Web Scraping Tool?
Web scraping tools (free or paid) and self-service software/applications can be a good choice if the data requirement is small, and the source websites aren’t complicated. Web scraping tools and software cannot handle large scale web scraping, complex logic, bypassing captcha and do not scale well when the volume of websites is high. For such cases, a full-service provider is a better and economical option.
Even though these web scraping tools extract data from web pages with ease, they come with their limits. In the long run, programming is the best way to scrape data from the web as it provides more flexibility and attains better results.
If you aren’t proficient with programming or your needs are complex, or you require large volumes of data to be scraped, there are great web scraping services that will suit your requirements to make the job easier for you.
You can save time and obtain clean, structured data by trying us out instead – we are a full-service provider that doesn’t require the use of any tools and all you get is clean data without any hassles.
Note: All the features, prices etc are current at the time of writing this article. Please check the individual websites for current features and pricing.
The basics of web scraping
It’s extremely simple, in truth, and works by way of two parts: a web crawler and a web scraper. The web crawler is the horse, and the scraper is the chariot. The crawler leads the scraper, as if by hand, through the internet, where it extracts the data requested. Learn the difference between web crawling & web scraping and how they work.
The crawler
A web crawler, which we generally call a “spider,” is an artificial intelligence that browses the internet to index and search for content by following links and exploring, like a person with too much time on their hands. In many projects, you first “crawl” the web or one specific website to discover URLs which then you pass on to your scraper.
The scraper
A web scraper is a specialized tool designed to accurately and quickly extract data from a web page. Web scrapers vary widely in design and complexity, depending on the project. An important part of every scraper is the data locators (or selectors) that are used to find the data that you want to extract from the HTML file — usually, XPath, CSS selectors, regex, or a combination of them is applied.
WebDrivers and browsers
Every web scraper uses a browser as it needs to connect to the destination URL. For testing purposes we highly recommend using a regular browser (or not a headless one), especially for newcomers. Seeing how written code interacts with the application allows simple troubleshooting and debugging, and grants a better understanding of the entire process.
Headless browsers can be used later on as they are more efficient for complex tasks. Throughout this web scraping tutorial we will be using the Chrome web browser although the entire process is almost identical with Firefox.
To get started, use your preferred search engine to find the “webdriver for Chrome” (or Firefox). Take note of your browser’s current version. Download the webdriver that matches your browser’s version.
If applicable, select the requisite package, download and unzip it. Copy the driver’s executable file to any easily accessible directory. Whether everything was done correctly, we will only be able to find out later on.
How do Web Scrapers Work?
So, how do web scrapers work? Automated web scrapers work in a rather simple but also complex way. After all, websites are built for humans to understand, not machines.
First, the web scraper will be given one or more URLs to load before scraping. The scraper then loads the entire HTML code for the page in question. More advanced scrapers will render the entire website, including CSS and Javascript elements.
Then the scraper will either extract all the data on the page or specific data selected by the user before the project is run.
Ideally, the user will go through the process of selecting the specific data they want from the page. For example, you might want to scrape an Amazon product page for prices and models but are not necessarily interested in product reviews.
Lastly, the web scraper will output all the data that has been collected into a format that is more useful to the user.
Most web scrapers will output data to a CSV or Excel spreadsheet, while more advanced scrapers will support other formats such as JSON which can be used for an API.

The basics of web scraping
It’s extremely simple, in truth, and works by way of two parts: a web crawler and a web scraper. The web crawler is the horse, and the scraper is the chariot. The crawler leads the scraper, as if by hand, through the internet, where it extracts the data requested. Learn the difference between web crawling & web scraping and how they work.
The crawler
A web crawler, which we generally call a “spider,” is an artificial intelligence that browses the internet to index and search for content by following links and exploring, like a person with too much time on their hands. In many projects, you first “crawl” the web or one specific website to discover URLs which then you pass on to your scraper.
The scraper
A web scraper is a specialized tool designed to accurately and quickly extract data from a web page. Web scrapers vary widely in design and complexity, depending on the project. An important part of every scraper is the data locators (or selectors) that are used to find the data that you want to extract from the HTML file — usually, XPath, CSS selectors, regex, or a combination of them is applied.
Инструменты
- Язык программирования и соответствующие библиотеки
Конечно, без него никуда. В нашем случае будет использован Python. Данный язык является довольно сильным инструментом для написания скраперов, если уметь правильно пользоваться им и его библиотеками: requests, bs4, json, lxml, re. - Инструменты разработчика
Каждый современный браузер имеет данную утилиту. Лично мне удобно пользоваться Google Chrome или Firefox. Если вы пользуетесь другим браузерами, рекомендую попробовать один из вышеперечисленных. Здесь нам понадобятся практически все инструменты: elements, console, network, application, debuger. - Современная IDE
Здесь выбор остаётся за вами, единственное, что хотелось бы посоветовать — наличие компилятора, debuger’a и статического анализатора в вашей среде разработке. Я отдаю своё предпочтение PyCharm от JetBrains.
Scraping multiple pages
Now that we know how to scrape a single page, it’s time to learn how to scrape multiple pages, like the entire product catalog.
As we saw earlier there are different kinds of Spiders.
When you want to scrape an entire product catalog the first thing you should look at is a sitemap. Sitemap are exactly built for this, to show web crawlers how the website is structured.
Most of the time you can find one at . Parsing a sitemap can be tricky, and again, Scrapy is here to help you with this.
In our case, you can find the sitemap here: https://clever-lichterman-044f16.netlify.com/sitemap.xml
If we look inside the sitemap there are many URLs that we are not interested by, like the home page, blog posts etc:
Fortunately, we can filter the URLs to parse only those that matches some pattern, it’s really easy, here we only to have URL that
have in their URLs:
You can run this spider as follow to scrape all the products and export the result to a CSV file:
Now what if the website didn’t have any sitemap? Once again, Scrapy has a solution for this!
Let me introduce you to the… .
The CrawlSpider will crawl the target website by starting with a list. Then for each url, it will extract all the links based on a list of .
In our case it’s easy, products has the same URL pattern so we only need filter these URLs.
As you can see, all these built-in Spiders are really easy to use. It would have been much more complex to do it from scratch.
With Scrapy you don’t have to think about the crawling logic, like adding new URLs to a queue, keeping track of already parsed URLs, multi-threading…
Парсинг
Парсить хорошо организованные куски HTML/XML намного проще, чем захламлённые страницы, так что всем, кто разобрался с парсингом в прошлой статье, в этой всё должно быть очевидно без объяснений. Блок кода парсинга будет выглядеть так:
Особенно стоит обратить внимание на метод из. Он работает точно также, как одноимённый метод у массивов
Конкретно здесь он используется перед для удаления из выборок пунктов списка первого пункта, который не несёт полезной информации. Но это не то, из-за чего метод стоит знать каждому скрейперу, использующему . Главное, что при тестировании скрейпинга сайтов с большими выборками можно перед вызовом метода each вызывать, например (ну, или в нашем случае), чтобы уменьшить выборку до приемлемых размеров. Скрейпинг будет работать полностью в боевом режиме, но не так долго.
(Важное примечание: если будете пробовать скрейпить LIS Map – обязательно используйте. Хабраэффект убивает.)
Scrapehero
|
Try Scrapehero |
Custom APIScalableScrapes complex JavaScript/AJAX sites, CAPTCHACustom Artificial Intelligence (AI/ML/NLP) based solutions to analyze the data |
If you are searching for a service that can convert billions of web pages into actionable data, ScrapeHero is the one for you!
From absolutely unstructured pieces of web data, ScrapeHero provides high-quality structured data to power your decision making with actionable intelligence.
The reason why countless customers love ScrapeHero is that you don’t need any software, hardware, scraping tools, or skills- they do it all for you.
For websites that don’t provide API or have rate-limited or date-limited API, ScrapeHero builds custom API so that you can integrate it into your business processes.
ScrapeHero is a sought-after service because of its outstanding scalability. It can crawl and scrape thousands of web pages per second and scrape billions of web pages every day. This is why a large number of the world’s iconic companies rely on ScrapeHero for its data.
However, it’s not just mechanical data extraction that you get; ScrapeHero has put in place AI-based quality checks to analyze data quality issues and fix them. Without compromising quality, ScrapeHero takes care of complex JavaScript/AJAX sites, CAPTCHA, IP blacklisting transparently.
ScrapeHero is much more than a typical web scraping service; they can build custom Artificial Intelligence (AI/ML/NLP) based solutions to analyze the data they gather for you.
ScrapeHero delivers data in JSON, CSV, Excel, XML and more. It beautifully integrates with cloud storage providers such as Amazon S3, DropBox, Microsoft Azure, Google Cloud Storage, and FTP.
Over and above this, you get top-notch customer support for any and every one of your requirements.
With a remarkable track record of web data extraction for some of the largest companies in the world, ScrapeHero has earned global recognition as a web scraping service.
Scrapehero’s Pricing
-
Business Plan :
$150 per website per month for scraping 10,000 pages
-
Enterprise Basic :
- $1000+ per month
- Monthly subscription required
- One-time set-up fees additional
- Scrape up to 1 million pages
-
Enterprise Premium
- $5000+ per month
- Monthly subscription required
- Setup fees included
- Scrape up to 1 million+ page
The Best Web Scraper
So, now that you know the basics of web scraping, you’re probably wondering what is the best web scraper for you?
The obvious answer is that it depends.
The more you know about your scraping needs, the better of an idea you will have about what’s the best web scraper for you. However, that did not stop us from writing our guide on what makes the Best Web Scraper.
Of course, we would always recommend ParseHub. Not only can it be downloaded for FREE but it comes with an incredibly powerful suite of features which we reviewed in this article. Including a friendly UI, cloud-based scrapping, awesome customer support and more.
Want to become an expert on Web Scraping for Free? Take our free web scraping courses and become Certified in Web Scraping today!
Обратная разработка
Jsdom — это быстрое и простое решение, однако можно найти более легкий подход.
Нужно ли вообще моделировать DOM?
Как правило, веб-страница, из которой нужно извлечь данные, состоит из HTML, JavaScript и других общеизвестных технологий. Таким образом, если найти кусочек кода, из которого получены необходимые данные, можно повторить ту же операцию для получения того же результата.
Проще говоря, этими данными могут быть:
- часть исходного кода HTML (как было сказано в первой части),
- часть статического файла, ссылка на который содержится в HTML-документе (к примеру, строка в файле javascript),
- ответ на сетевой запрос (к примеру, код JavaScript оправляет запрос AJAX к серверу и получает ответ строкой JSON).
Доступ к этим источникам данных можно получить с помощью сетевых запросов. С нашей точки зрения, не имеет значения, использует ли веб-страница HTTP, WebSockets или любой другой протокол связи, поскольку все они воспроизводимы в теории.
После нахождения ресурса, содержащего данные, можно отправить аналогичный сетевой запрос к тому же серверу, как и в исходной странице. В результате вы получаете ответ, содержащий необходимые данные, которые можно с легкостью извлечь с помощью регулярных выражений, методов string, JSON.parse и т. д.
Проще говоря, можно просто взять ресурс, в котором расположены данные, вместо того, чтобы обрабатывать и загружать все сразу. Таким образом, проблема, показанная в предыдущих примерах, решается с помощью одного HTTP-запроса.
В теории это решение выглядит простым, однако в большинстве случаев его выполнение занимает много времени и требует опыта работы с веб-страницами и серверами.
Поиски можно начать с наблюдения за сетевым трафиком. Для этого есть отличный инструмент Network tab в Chrome DevTools. Он отобразит все исходящие запросы с ответами (включая статические файлы, запросы AJAX и т. д.), которые можно просмотреть в поисках данных.
Процесс может замедлиться, если ответ был изменен фрагментом кода перед отображением на экране. В этом случае, нужно найти этот кусочек кода и разобраться, в чем дело.
Как можно заметить, это решение может потребовать еще больше работы, чем предыдущие методы. С другой стороны, после реализации оно предоставляет наилучшую производительность.
Этот график отображает необходимое время выполнения и размер пакета в сравнении с Jsdom и Puppeteer:
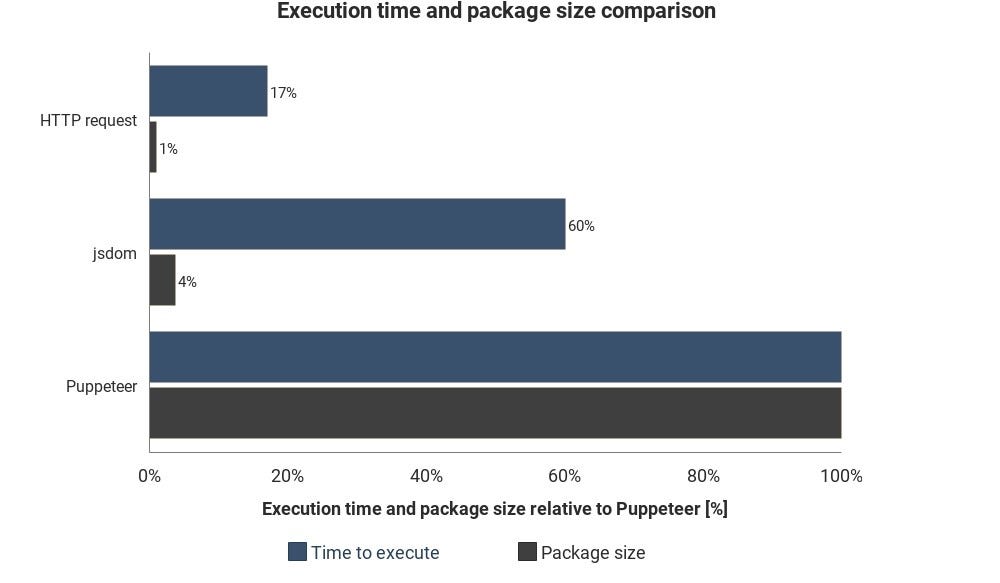
Результаты могут варьироваться в зависимости от ситуации, они лишь показывают примерную разницу между этими техниками.
Интеграция облачного сервиса
Допустим, вы реализовали одно из перечисленных решений. Один из способов выполнения сценария — включить компьютер, открыть терминал и запустить его вручную.
Однако все можно упростить, загрузив сценарий на сервер. Он будет выполнять код систематически в зависимости от настроек.
Это можно сделать, запустив сервер и настроив параметры выполнения сценария. Сервера светятся при наблюдении за элементом на странице. В других случаях облачная функция, вероятно, является более простым способом.
Облачные функции — это контейнеры, предназначенные для выполнения загруженного кода при появлении определенного события. Это означает, что не нужно управлять серверами, все выполняется автоматически с помощью выбранного облачного провайдера.
Популярные облачные провайдеры: Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Все они обладают сервисной функцией:
- AWS Lambda
- GCP Cloud Functions
- Azure Functions
Google’s Cloud Functions — лучшее решение при использовании Puppeteer. Размер сжатого пакета Headless Chrome (~130MB) превышает лимит максимального сжатого размера AWS Lambda (50MB). Есть несколько техник выполнения для Lambda, однако функции GCP поддерживают headless Chrome по умолчанию. Нужно просто включить Puppeteer в качестве зависимости в package.json.
Вывод
Для реализации каждого решения вам понадобится заглянуть в документацию и прочитать несколько статей. Однако я надеюсь, что вы получили базовое представление о техниках, используемых для сбора данных с веб-страниц и продолжите дальнейшее изучение.
Octoparse
Website: https://www.octoparse.com/
Who this is for: Octoparse is a fantastic scraper tool for people who want to extract data from websites without having to code, while still having control over the full process with their easy-to-use user interface.
Why you should use it: Octoparse is one of the best screen scraping tools for people who want to scrape websites without learning to code. It features a point-and-click screen scraper, allowing users to scrape behind login forms, fill in forms, input search terms, scrolls through infinite scroll, render JavaScript, and more. It also includes a site parser and a hosted solution for users who want to run their scrapers in the cloud. Best of all, it comes with a generous free tier allowing users to build up to 10 crawlers for free. For enterprise-level customers, they also offer fully customized crawlers and managed solutions where they take care of running everything for you and just deliver the data to you directly.
Создание tasks.py с помощью Celery
Приведенный выше пример помог проверить процесс, который мы будем использовать для выполнения задач с помощью Celery, а также продемонстрировал, как задачи регистрируются с помощью Celery worker.
Основываясь на приведенном выше примере, мы начнем с создания задач скрапинга. Сейчас я собираюсь отказаться от файла scraping.py, так как он будет просто скопирован в файл tasks.py для простоты.
Я начну с удаления из примера функции def add(x, y) и копирования зависимостей (Requests и BeautifulSoup) вместе с самими функциями.
Примечание: я буду использовать те же функции, но в файле tasks.py.
# tasks.py
from celery import Celery
import requests # ввод данных
from bs4 import BeautifulSoup # парсинг xml
import json # экспорт в файлы
app = Celery('tasks')
# функция сохранения
def save_function(article_list):
with open('articles.txt', 'w' as outfile:
json.dump(article_list, outfile)
# функция скрапинга
def hackernews_rss():
article_list = []
try:
# выполняем запрос, разбираем данные с помощью XML
# разбираем данные в BS4
r = requests.get('https://news.ycombinator.com/rss')
soup = BeautifulSoup(r.content, features='xml')
# выбираем только "item", которые нам нужны из данных
articles = soup.findAll('item')
# для каждого "item" разбираем его в список
for a in articles:
title = a.find('title').text
link = a.find('link').text
published = a.find('pubDate').text
# создаем объект "article" с данными
# из каждого "item"
article = {
'title': title,
'link': link,
'published': published
}
# добавляем "article_list" с каждым объектом "article"
article_list.append(article)
# после цикла вносим сохраненные объекты в файл .txt
return save_function(article_list)
except Exception as e:
print('The scraping job failed. See exception: ')
print(e)
Упомянутые выше функции парсинга веб-страниц теперь доступны в файле вместе с их зависимостями. Следующим шагом является регистрация задач в приложении Celery, для этого просто размещаем над каждой функцией.
# tasks.py...
# то же, что и выше
@app.task
def save_function(article_list):
...@app.task
def hackernews_rss():