Единицы измерения информации
Содержание:
- Таблица перевода величин: бит, байт, Кб, Мб, Гб, Тб
- Функции объединения и разделения
- Функции замены
- Introducing byte beats
- Присваивания литералов
- Префиксы, суффиксы и удаление
- Байтить в «Доте»
- Демаркация
- Работа с данными
- Исторический
- Функции сравнения
- Почему HDD в 1Гб не равен 1000 Мб
- Практическое использование
- Байт и байты!
- Краткое отступление о строках и байтах
- Бинарный (двоичный)!
- Sounds! Comment replies!
- Приставки К, М, Г, Т («кило-», «киби-» и т.д.)
- Бит и байт — минимальные единицы измерения информации
Таблица перевода величин: бит, байт, Кб, Мб, Гб, Тб
Существует таблица всех величин, которые используются в современных жестких дисках, других носителях информации, а также файлах.
Она создана специально для удобства точного определения объемов информации и дана ниже. В нее включены только те единицы измерения, которые можно увидеть и применить в реальной жизни.
После терабайта измерение хоть и ведется, однако на уровне науки и высоких технологий, а не повседневной жизни.
| Название | Обозначение | Пересчет в байты |
|---|---|---|
| Бит | — | Наименьшее значение |
| Байт | Б, b | 8 бит |
| Килобайт | Кб, Kb | 1024 байт |
| Мегабайт | Мб, Mb | 1024 килобайт |
| Гигабайт | Гб, Gb | 1024 мегабайт |
| Терабайт | Тб, Tb | 1024 гигабайт |
С помощью этой таблицы также можно рассчитать фактическую скорость вашего интернет-соединения.
Достаточно просто определить, сколько бит в секунду передается к вам на компьютер, полученное значение разделить на 8, и потом на 1024.
Например, на скорости 100 Мб/сек в одну секунду вам будет передаваться примерно 12 мегабайт информации.
Недостаток таблицы заключается в том, что по ней можно определить только ровные значения, встретить которые можно нечасто.
Для того, чтобы точно определить вес файла или объем жесткого диска, можно воспользоваться онлайн-конвертером, который представлен чуть ниже.
Функции объединения и разделения
Довольно часто приходится работать со строками, содержащими разделители, по которым строку нужно разбивать. Например, пути в UNIX объединены двоеточиями, а формат CSV это, по сути, просто данные, записанные через запятую.
Разбиение строк
Для простого разбиения слайсов или подстрок, у нас есть Split()-функции:
Эти функции разбивают строку или слайс байт согласно разделителю и возвращают их в виде нескольких слайсов или подстрок. After()-функции включают и сам разделитель в подстроках, а N()-функции ограничивают количество возвращаемых разделений:
Разбиение строк является очень частой операцией, но обычно это происходит в контексте работы с файлом в формате CSV или UNIX-путей. Для таких случаев я использую пакеты encoding/csv и path соответственно.
Разбиение по категориям
Иногда вам понадобится указывать разделители в виде набора рун, а не серии рун. Наилучшим примером тут будет разбиение слов по пробелам разной длины. Просто вызвав с пробелом в качестве разделителя, вы получите на выходе пустые подстроки, если на входе есть несколько пробелов подряд. Вместо этого, используйте функцию :
Она трактует последовательные пробелы, как один разделитель:
Функция Fields() это простой враппер вокруг другой функции — FieldsFunc(), которая позволяет указать произвольную функцию для проверки рун на разделитель:
Объединение строк
Другая операция, которая часто используется при работе с данными — это объединение слайсов и строк. Для этого есть функция :
Одна из ошибок, которую я встречал, заключается в том, что разработчики пытаются реализовать объединение строк вручную и пишут что-то вроде:
Проблема с этим кодом в том, что в нём происходит очень много аллокаций памяти. Так как строки неизменяемы, каждая итерация создаёт новую строку. Функция же использует слайс байт в качестве буфера и конвертирует в строку в самом конце. Это минимизирует количество аллокаций памяти.
Функции замены
Простая замена
Иногда необходимо заменить подстроку или часть слайса. Для большинства простых случаев всё что вам нужно, это функция :
Она заменяет любое вхождение old в вашей строке на new. Если значение n равно -1, то будут заменены все вхождения. Эта функция очень хорошо подходит, если нужно заменить простое слово по шаблону. Например, вы можете позволить пользователю использовать шаблон «$NOW» и заменить его на текущее время:
Если вам необходимо заменять сразу несколько различных вхождений, используйте . Он принимает на вход пары старое/новое значение:
Замена регистра
Вы можете полагать, что работа с регистрами это просто — нижний и верхний, всего-то делов — но Go работает с Unicode, а Unicode никогда не бывает прост. Есть три типа регистров: верхний, нижний и заглавный регистры.
Верхний и нижний довольно просты для большинства языков, и достаточно использовать функции и :
Но, в некоторых языках правила регистров отличаются от общепринятых. К примеру, в турецком языке, i в верхнем регистре выглядит как İ. Для таких специальных случаев, есть специальные версии этих функций:
Далее, у нас есть ещё заглавный регистр и функция :
Наверное вы очень удивитесь, когда увидите что переведёт все ваши символы в верхний регистр:
Это потому, что в Unicode заглавный регистр является специальным видом регистра, а не написанием первой буквы в слове в верхнем регистре. В большинстве случаев, заглавный и верхний регистр это одно и тоже, но есть несколько code point-ов, в которых это не так. Например, code point lj (да, это один code point) в верхнем регистре выглядит как LJ, а в заглавном — Lj.
Функция, которая вам нужна в этом случае, это, скорее всего, :
Её вывод будет более похож на правду:
Маппинг рун
Есть ещё один способ замены данных в слайсах байт и строках — функция :
Эта функция позволяет указать свою функцию для проверки и замены каждой руны. Если честно, я понятия не имел об этой функции, пока не начал писать этот пост, поэтому никакой личной истории использования не могу тут поведать.
Introducing byte beats
March 11, 2020

Today we are bringing a new, fun feature to our iOS app: byte beats. They’re perfectly looping little audio tracks.
We automatically stretch or shorten the beats to fit your byte, so you don’t have to do the work. The perfect loop means when it plays over and over again, you can’t tell where the sound begins or ends. The best way to see what we mean is to try it for yourself.
In the app, there’s a library of audio options. We will be working with, and paying, beat creators to add new ones each week. If you want to make byte beats, let us know here and we’ll be in touch.
Android users: we are working hard to bring this feature to our Android app and will share more info when it’s ready. Thanks for your patience.
Присваивания литералов
можно объявить и инициализировать переменную, назначив ей десятичный литерал, шестнадцатеричный литерал, восьмеричный литерал или (начиная с Visual Basic 2017) двоичный литерал. Если целочисленный литерал находится вне диапазона (то есть если он меньше Byte.MinValue или больше Byte.MaxValue ), возникает ошибка компиляции.
В следующем примере целые числа, равные 201, представленные в виде десятичных, шестнадцатеричных и двоичных литералов, неявно преобразуются из типа Integer в значения.
Примечание
Используйте префикс или , чтобы обозначить шестнадцатеричный литерал, префикс или обозначить двоичный литерал, а также префикс или обозначить Восьмеричный литерал. У десятичных литералов префиксов нет.
начиная с Visual Basic 2017, можно также использовать символ подчеркивания () в качестве разделителя цифр, чтобы улучшить удобочитаемость, как показано в следующем примере.
начиная с Visual Basic 15,5, можно также использовать символ подчеркивания () в качестве начального разделителя между префиксом и шестнадцатеричными, двоичными или восьмеричными цифрами. Пример:
Чтобы использовать символ подчеркивания в качестве начального разделителя, нужно добавить в файл проекта Visual Basic (*.vbproj) следующий элемент:
дополнительные сведения см. в разделе выбор версии Visual Basic языка.
Префиксы, суффиксы и удаление
Префиксы в программировании вам встретятся довольно часто. Например, пути в HTTP адресах часто сгруппированы по функционалу с помощью префиксов. Или, другой пример — специальный символ в начале строки, вроде «@», используется для упоминания пользователя.
Функции и позволяют вам проверить такие случаи:
Эти функции могут показаться слишком простыми, чтобы с ними заморачиваться, но я регулярно вижу следующую ошибку, когда разработчики забывают на проверку нулевого размера строки:
Этот код выглядит просто, но если str окажется пустой строкой, вы получите панику. Функция содержит эту проверку:
Удаление
Термин «удаление»(trimming) в пакетах bytes и strings означает удаление байт или рун в начале и/или конце слайса или строки. Сама обобщённая для этого функция — :
Она удаляет все руны из набора cutset с обеих сторон — с начала и конца строки. Также можно удалять только с начала, или только с конца, используя и соответсвенно.
Но чаще всего используются более конкретные варианты удаления — удаление пробелов, для этого есть функция :
Вы можете подумать, что удаления с cutset-ом равным «\n\r» может быть достаточно, но TrimSpace() умеет удалять также символы пробелов, определённые в Unicode. Сюда входят не только пробелы, перевод строки или символ табуляции, но и такие нестандартные символы как «thin space» или «hair space».
, на самом деле, всего лишь над , которая определяет символы, которые будут использоваться для удаления:
Таким образом можно очень просто создать свою функцию, которая будет удалять, скажем, только пробелы в конце строки:
В заключение, если вы хотите удалить не символы, а конкретную подстроку слева или справа, то для этого есть функции и :
Они идут рука об руку с функциями и для проверки на наличие префикса или суфикса соответственно. Например, я использую их для bash-подобного дополнения путей конфигурационных файлов в домашней директории:
Байтить в «Доте»
Термин «байтить» используется в онлайн-играх, а если точнее в «Доте». Что значит байтить в «Доте»? Кто такие байтеры в онлайн-стратегиях? Разберем эти вопросы.
Любому, кто только зарегистрировался в онлайн-шутере (термин заимствован с английского языка и означает — «стрелок», то есть онлайн-стрелялки) или в играх жанра МОВА (это компьютерные игры, которые сочетают в себе элементы стратегии и компьютерных ролевых направлений), будет интересно узнать, что значит «байтить» или «байт».
В этом случает, значение термина полностью соответствует его переводу. Слово «байт» с английского означает «наживка» или «приманка».
То есть, жаргон означает: совершать определенные действия в игре, которые позволят путем хитрости победить противника, подсунув ему «приманку». В игре это происходит примерно так.
Игроки посоветовавшись, выбирают одного персонажа, который и будет играть роль наживки. Все остальные поджидают противника в засаде.
Игрок-наживка должен забайтить врага, противники начинают с ним бой, но в этот момент союзники выходят из засады и оказываются в более выгодном положении. Байтинг — это очень удачная тактика в большинстве современных онлайн-игр, ее применяют также и в «Доте 2».
Это еще одна из версий, которая раскрывает смысл, что значит байтить. А теперь узнаем, кто же выполняет роль той самой «наживки».
Демаркация
Что именно обозначает байт, определяется немного по-разному в зависимости от области применения. Этот термин может означать:
- единица измерения для объема данных из 8 бит с блоком символом «B», в результате чего порядок отдельных бит не важен. Символ единицы не следует путать с символом единицы «B», принадлежащим единице Bel .
- упорядоченная компиляция ( ) из 8 бит, формальное обозначение которой в соответствии с ISO — октет (1 байт = 8 бит). Иногда октет делится на две половины ( полубайта ) по 4 бита каждая, при этом каждый полубайт может быть представлен шестнадцатеричным числом . Таким образом, октет может быть представлен двумя шестнадцатеричными цифрами.
- наименьший объем данных определенной технической системы , обычно адресуемый через адресную шину . Количество бит на символ почти всегда является натуральным числом. Примеры:
- для телекса : 1 символ = 5 бит
- Для компьютеров семейства PDP : 1 символ = бит = приблизительно 5,644 бит (код Radix 50). По сравнению с 6 битами это приводит к экономии нескольких бит на символьную строку , которые могут использоваться, например, для целей управления. Однако границы байтов проходят сквозь биты, что может затруднить анализ содержимого.бревно2(50){\ displaystyle \ log _ {2} (50)}
- для IBM 1401 : 1 символ = 6 бит
- с ASCII : 1 символ = 7 бит
- для IBM-PC : 1 символ = 8 бит = 1 октет
- с Nixdorf 820 : 1 символ = 12 бит
- Для компьютерных систем типов UNIVAC 1100/2200 и OS2200 Series: 1 символ = 9 бит (код ASCII) или 6 бит (код FIELDATA)
- Для компьютеров семейства PDP-10 : 1 символ = 1… 36 бит, длина байта выбирается произвольно.
- типа данных в языках программирования . Количество бит на байт может варьироваться в зависимости от языка программирования и платформы (в основном 8 бит).
- ISO- определяет 1 байт как непрерывную последовательность не менее 8 бит.
Сегодня в большинстве компьютеров эти определения (наименьшая адресуемая единица, тип данных в языках программирования, тип данных C) объединяются в одно и имеют одинаковый размер.
Из-за широко распространенного использования систем, основанных на восьми битах (или степени двойки), термин «байт» используется для обозначения 8-битного размера, который на формальном языке (согласно стандартам ISO) правильно является октетом (от английского octet ) называется. В немецком языке термин «байт» (в смысле 8 бит) используется как единица измерения для спецификаций размера. Во время передачи байт может передаваться параллельно (все биты одновременно) или последовательно (все биты один за другим). Проверочные биты часто добавляются для проверки правильности . Для передачи больших объемов возможны дополнительные протоколы связи . На 32-битных компьютерах 32 бита (четыре байта) часто передаются вместе за один шаг, даже если необходимо передать только 8-битный кортеж. Это позволяет упростить алгоритмы, необходимые для расчета, и уменьшить набор команд для компьютера.
Как и в случае с другими юнитами, рядом с полным названием юнитов, соответственно, есть символ юнита . Для бита и байта это:
| Сокращенное название | полное имя |
|---|---|
| бит (редко «б») | немного |
| B (редко «байт») | байт |
Полное имя в основном подвержено нормальному склонению . Из-за большого сходства сокращений с письменными названиями единиц, а также с соответствующими формами множественного числа в английском языке, сокращения единиц «бит» и «байт» иногда снабжены множественным числом s.
Работа с данными
Информация — это всё то, что мы можем видеть, слышать, или же читать. При этом, объёмы этой самой информации постоянно растут и хранить, а также систематизировать её становится всё сложнее. Сам же компьютер обрабатывает информационные блоки с помощью устройств, расположенных внутри системного блока. Между тем или иным узлом информация передаётся за счёт наличия кабелей.
Даже с помощью таких внешних устройств, как клавиатура или мышка, Вы всё равно вносите дополнительную информацию в свой компьютер, которую необходимо будет обрабатывать и в дальнейшем хранить. В быту данные, важные для нас, хранятся в записной книжке, блокноте или ежедневнике.
С компьютером всё обстоит иначе. Он вынужден фиксировать любую информацию и для хранения использует специальные носители, включая жёсткий диск. Несмотря на его компактные размеры, на самом деле в устройстве может храниться невероятное количество данных, включая миллионы документов, тысячи аудиозаписей и видеороликов.
При этом, воспринимать информацию компьютер способен не так, как наш мозг, а в кодовом эквиваленте «0» или «1». На этом и базируется двоичная система, в которой участвуют всего две цифры. Именно одна из них называется битом, который является самым маленьким носителем компьютерной информации. При этом, само устройство может как хранить биты, так и передавать их.
Исторический
Количество бит, которое процессор должен потреблять для выполнения машинной инструкции , называется словом , его размер определяется конструктором. В первые дни вычислительной техники количество процессоров было ограниченным, поэтому они употребляли это слово небольшими порциями, соответствующими количеству битов на шине данных . Таким образом, термин Byte был придуман в 1956 году Вернером Бухгольцем, когда он работал над дизайном IBM Stretch . Это преднамеренное искажение английского слова bite , буквально «укус», чтобы избежать путаницы с битом путем исключения последнего
e.
Байт был также блок памяти для хранения символа. В английском языке слово « char » ( сокращение от символа ) часто используется для обозначения « байта », и наоборот. Каждый конструктор определяет размер байта в соответствии со своими текущими потребностями. В 1950-х и 1960-х годах байт часто состоял из 6 бит, потому что все символы, необходимые для программирования на английском языке, можно было закодировать шестью битами (64 варианта). Байты также могут быть 9 бит в размерах на других системах. PDP-10 имела еще одно определение байта с переменным размером, в пределах от 1 до 36 бит в зависимости от машинной команды для выполнения.
В большинстве аппаратных архитектур емкость компьютерной памяти обычно выражается в байтах , тогда как в «общедоступных» архитектурах на французском языке она выражается в байтах. Обобщение восьмибитных байтов усиливает эту путаницу, подводя черту под старые архитектуры, в основном североамериканские . Существует множество документации на французском языке, в которой неправильно выражается объем памяти в байтах из-за путаницы между байтами и байтами во время перевода.
Сегодня для мультимедиа словарь — Аудиовизуальное, IT, телекоммуникации из AFNOR , то байт это «информационный блок , соответствующий одному из байте 8 бит.» Стандартизация IEC 80000-13 идет в том же направлении: стандартизировать размер байтов до 8 бит. Именно из-за этой 8-битной «нормализации» возникает путаница.
Однако, как в английском, так и во французском языках, если мы хотим явно обозначить количество в восемь бит, мы используем слово « октет »; в то время как, если мы хотим выразить адресную единицу независимо от количества бит, мы используем слово « байт ». Таким образом, формальное описание языка программирования будет сознательно использовать слово « байт», если язык не требует, чтобы байт был размером в один байт . Это, например, случай языка C , где байт может содержать более восьми бит. Слово «октет» сознательно используется во французском языке, как и в английском, для описания формата данных с точностью до бита. Таким образом, мы находим слово «байт» в английском тексте как RFC 793, который описывает протокол связи TCP с Интернетом , или в стандарте H.263, который описывает стандарт кодирования цифрового видео.
Таким образом, такое же различие между « байтом » и «байтом» существует в обоих языках, только слово, которое обычно используется в случаях, когда байт измеряет восемь битов, изменяется.
Функции сравнения
Когда у вас есть два слайса байт или две строки, вам может понадобится получить ответ на два вопроса. Первый — равны ли эти два объекта? И второй — какой из объектов идёт раньше при сортировке?
Равенство
Функция отвечает на первый вопрос:
Эта функция есть только в пакете bytes, так как строки можно сравнивать с помощью оператора ==.
Хотя проверка на равенство может показаться простой задачей, есть популярная ошибка в использовании для проверки на равенство без учёта регистра:
Этот подход неправильный, он использует 2 аллокации для новых строк. Гораздо более правильный подход это использование :
Слово Fold тут означает Unicode case-folding. Оно охватывает правила для верхнего и нижнего регистра не только для A-Z, но и для других языков, и умеет конвертировать φ в ϕ.
Сравнение
Чтобы узнать порядок для сортировке двух слайсов байт или строк, у нас есть функция :
Эта функция возвращает -1, если a меньше b, 1, если a больше b и 0, если a и b равны. Эта функция присутствует в пакете strings исключительно для симметрии с bytes. Russ Cox даже призывает к тому, что «никто не должен использовать strings.Compare». Проще использовать встроенные операторы < и >.
Обычно вам нужно сравнивать слайсы байт или строк при сортировке данных. Интерфейс нуждается в функции сравнения для метода Less(). Чтобы перевести тернарную форму возвращаемого значения Compare() в логическое значение для Less(), достаточно просто проверить на равенство с -1:
Почему HDD в 1Гб не равен 1000 Мб
Исходя из объяснения выше, один гигабайт больше, чем тысяча мегабайт ровно на 24 единицы. Поэтому в характеристиках на жестких дисках пишут точно – сколько составляет их объем. Округлять эти величины также нельзя.
Соответственно, 8 гигабайт оперативной памяти составляет не 8000 мегабайт, а 8192.
Именно по этой же причине иногда при покупке носителя информации его объем составляет немного меньше, чем написано в характеристиках.
Ровного значения просто не может быть, поэтому нередко вместо обещанных десяти гигабайт обнаруживается девять.
Где используются эти величины?
Как уже было сказано выше – эти термины применяются в компьютерной IT-сфере.
Например, при обозначении вместительности HDD. Современные жесткие диски уже имеют емкость больше одного терабайта, и продолжают расширяться.
С флешкартами и другими переносными носителями все скромнее – их максимальный объем может достигать 128 гигабайт.
Этими же терминами обозначается объем файлов.
Разброс в этом плане гораздо больше, бывают случаи, когда объемный и большой пласт информации весит несколько гигабайт, или же текстовый файл, занимающий всего пару килобайт.
Еще интереснее дела обстоят с оперативной памятью компьютера.
Ее объем также измеряется в ячейках памяти, и сейчас многие профессиональные машины оборудованы несколькими плашками RAM, общий размер которых может достигать 128 гигабайт.
Это обусловлено тем, что на обработку информации необходимо все больше и больше ресурсов – и для того, чтобы программа работала стабильно, во временной памяти должно быть много места.
А есть ли больше?
Существуют ли величины больше, чем терабайт? Да, конечно, они есть.
- 1024 терабайт – это 1 петабайт.
- 1024 петабайта – 1 экзабайт.
Дело в том, что современные технологии еще не дошли до создания носителей и уж тем более файлов, объемом и размером хотя бы приближенным к этим величинам – поэтому в повседневной жизни они используются крайне редко.
Однако, они широко используются для компьютерных расчетов в науке и высоких технологиях.
С учетом того, насколько быстро сейчас идет технологический прогресс – не исключено, что через пару лет на прилавках появятся жесткие диски объемом в 1024 терабайт
Практическое использование
В электронной обработке данных наименьшая возможная единица хранения называется битом . Бит может иметь два возможных состояния, которые обычно обозначаются как «ноль» и «единица». Во многих языках программирования тип данных « логический » (или «логический» или «логический») используется для одного бита . Однако по техническим причинам фактическое отображение логического значения обычно имеет форму слова данных (« WORD »).
Восемь таких битов объединяются в единицу — так сказать пакет данных — и обычно называются байтом. С другой стороны, официальное обозначение в соответствии с ISO — октет: 1 октет = 1 байт = 8 бит. Многие языки программирования поддерживают тип данных с именем «byte» (или «byte» или «BYTE»), при этом следует отметить, что, в зависимости от определения , это может использоваться как целое число , как набор бит , как элемент набора символов или, в случае языков программирования с неопределенным типом, может использоваться даже одновременно для нескольких из этих типов данных, так что больше не будет никакой совместимости по присваиванию .
Байт — это стандартная единица для обозначения емкости хранилища или количества данных. Это включает в себя размеры файлов, емкость постоянных носителей ( жестких дисков , компакт — диски , DVD — диски , Blu-Ray диски , дискеты , устройства хранения USB массового и т.д.) и способность многих энергонезависимых запоминающих устройств (например, ). С другой стороны, скорости передачи (например, максимальная скорость подключения к Интернету) обычно указываются в битах.
Байт и байты!
Когда мы объединяем восемь битов, мы формируем байт. Байт — это человеческое понятие, а не то, что компьютер может понять по своей сути. Очень рано разработчики компьютеров решили создавать байты из 8 бит. Давайте посмотрим, сколько комбинаций мы можем создать, используя восемь битов, установленных в состояние 0 или 1:
0000 0000 = 0 0000 0001 = 1 0000 0010 = 2 0000 0011 = 3 ... 0000 1000 = 8 0000 1001 = 9 ... 0100 0000 = 64 ... 1000 0000 = 128 1000 0001 = 129 1000 0010 = 130 ... 1111 1111 = 255
Слева — двоичное число, справа — десятичное.
Есть ровно 256 возможных комбинаций (от 0 до 255). Несмотря на то, что у нас есть только восемь маленьких металлических частей и один магнит, теперь мы можем сохранить 255 различных состояний, просто намагничивая или размагничивая любой из восьми металлических предметов. Это много? Возможно, но если учесть, что простой PDF-файл с несколькими отсканированными страницами может легко иметь размер 10 мегабайт (= 10 000 000 байт или 80 000 000 бит), вы можете задаться вопросом, как любой компьютер может обрабатывать 80 миллионов маленьких кусочков металла
Ещё более удивительно то, что у многих людей скорость подключения к Интернету составляет 50 Мбит/с (мегабит в секунду) или больше. 50 Мбит/с — это 6 250 000 байт в секунду, что, в свою очередь, составляет поразительные 50 000 000 бит в секунду. В этом случае данные не хранятся на намагниченных металлических деталях.
Следующий вопрос, который может прийти в голову, — куда записываются эти биты? В любой форме хранения в вычислительной системе. Например, основной чип памяти в вашем компьютере, или просто физический диск, например, более старый тип HDD (Hard Disk Drive), у которого были буквально вращающиеся намагничиваемые диски внутри, а маленькая головка двигалась взад и вперёд. в то время как диски вращались со скоростью 5400, 7000 или 10000 оборотов в минуту и намагничивали или размагничивали биты (1 или 0).
У компьютера также есть другие места, где он может хранить информацию, например кеши уровня 1 и уровня 2 (и, если применимо, уровня 3 и т. д.) Внутри ЦП (центрального процессора). Итак, каковы некоторые из максимальных скоростей, при которых компьютеры могут намагничивать и размагничивать биты?
Добро пожаловать в самые быстрые диски в мире: быстрые современные NVMe (тип твердотельного накопителя, который, в свою очередь, является преемником жёсткого диска) могут достигать скорости последовательной записи 7000 МБ/с, то есть 56000000000 физических магнитных битов записывается в секунду. Невероятно, но реально.
Иногда полезно вернуться немного назад в историю и в то, как всё работает, чтобы оценить то, что было достигнуто, и понять, с какой невероятной скоростью мы прогрессируем. На самом деле это то, что происходит внутри вашего компьютера каждую секунду, и это происходит ещё чаще и быстрее, когда вы обрабатываете интенсивную рабочую нагрузку. Круто?
Краткое отступление о строках и байтах
Роб Пайк написал отличный и глубокий пост о строках, байтах, рунах и символах, но для этого поста я бы хотел дать более простое определение с точки зрения разработчика.
Слайс байт представляет собой изменяемый последовательный набор байт. Слегка многословно, поэтому давайте попробуем понять, что это значит.
У нас есть слайс байт:
Он изменяемый, поэтому вы можете изменять в нём элементы:
Вы также можете менять его размер:
И он последовательный, так как байты в памяти идут один за другим:
Строки же представляют собой неизменяемый последовательный набор байт фиксированного размера. Это означает, что вы не можете изменять строки — только создавать новые
Это важно понимать в контексте производительности программы. В программах, где нужна очень высокая производительность, постоянное создание большого количества строк создаст ощутимую нагрузку на сборщик мусора
С точки зрения разработчика, строки лучше использовать, когда вы работаете с данными в UTF-8 — они могут быть использованы как ключи к map, в отличие от слайсов байт, например, и большинство API используют строки для представления строковых данных. С другой стороны, слайсы байт гораздо лучше подходят, когда вам нужно работать с сырыми байтами, при обработке потоков данных, например. Они также удобней, если вы хотите избежать новых выделений памяти и хотите переиспользовать память.
Бинарный (двоичный)!
Теперь, когда мы рассмотрели биты и байты, мы можем сделать небольшой шаг вперёд и перейти к понятию «двоичный». Двоичный как термин может использоваться как указатель двоичного числа (как в нашем однобайтовом примере выше, где мы перешли от 0000 0000 (десятичное 0) до 1111 1111 (десятичное число 255)), или как поток, некоторые данные или состояние.
Например, мы можем говорить о двоичном потоке данных, когда говорим о нулях и единицах, перемещающихся по компьютерной сети. В таком случае (двоичный поток данных) состояние битов не намагничивается или размагничивается, как когда они хранятся на диске или в кэше, а скорее меняется напряжение (например, +5 Вольт), чтобы указать состояние 1 и ноль вольт, чтобы указать состояние 0.
Мы можем использовать слово двоичный для обозначения данных, хранящихся как двоичные (например, на диске), или как состояние, например, исполняемый файл на компьютере часто называется двоичным. Все эти разные виды использования слова «двоичный» требуют немного времени, чтобы привыкнуть к жаргону.
Sounds! Comment replies!
July 22, 2020
Now you can make bytes with sounds. Make bytes using sounds from other people’s posts by tapping the button in the top right corner. Or upload your own from videos in your library, and then give them a name and custom artwork.
We built sounds quickly — it’s been a popular request. As such, there’s some functionality we haven’t gotten to yet. Here’s what’s coming:
- Ability to see and use sounds from all bytes (Note: as a creator, you can edit old bytes and turn on the sound for others to use.)
- Search and favorite sounds
- Create sounds from popular music
- Also, you can now reply to and like comments.
This feature is rolling out on iOS today and will be coming to Android shortly. We appreciate the continued feedback. ️
Приставки К, М, Г, Т («кило-», «киби-» и т.д.)
…чтобы измерять большие объемы данных, используют кратные приставки (это как «килограмм»). Привычная же нам приставка «кило-» означает умножение на 1000 (103), но в двоичной системе счисления используют два в десятой степени (210).
Давайте же вместе с сайтом IT-уроки разберемся в этом запутанном вопросе.
История введения двоичных приставок
Для обозначения величины 210=1024 байт, ввели двоичную приставку «К» (именно прописная буква «К»), но в разговорной речи единицу «К» стали называть «кило», что не совсем одно и то же. Чтобы избежать путаницы, ввели названия приставкам:
Т.е. второй слог изменили с привычного на «би», «бинарный».
Но путаница не исчезла, многие расшифровывали «К» и «М» привычными «кило» и «мега». Даже международные стандарты по-разному интерпретировали расшифровку двоичных приставок. Кроме того, производители добавили масла в огонь внесли свой вклад в запутывание ситуации (одни считали 210, другие 103).
В итоге, чтобы окончательно убрать несоответствие, изменили не только названия, но и приставки:
Как Вы думаете, помогло? Конечно же, нет
В обиходе говорят «кило», в программах ОС Windows пишут «К», в Linux обозначают «Ки», производители жестких и оптических дисков пишут «К», а имеют в виду «Ки» и т.д.
Что же делать обычному пользователю?
Если подвести итог всему сказанному, то на сегодняшний день три варианта использования двоичных приставок, их мы и сведем в три таблицы.
1. Обычное использование двоичных приставок
В свойствах файлов почти все программы, да и сама операционная система Windows использует приставку в виде прописной буквы «К», «М», «Г» и т.д. Производители оперативной памяти используют тот же принцип. То есть можно пользоваться следующей таблицей:

Двоичные приставки в ОС Windows и у производителей ОЗУ 1 Кбайт (КБ или KB или Kbyte) = 1024 байт
Эта «К» на самом деле двоичная приставка «киби» (а не «кило», как все говорят).
2. Правильное использование двоичных приставок
В других операционных системах, а также в профессиональных обзорах серьезных ИТ-изданий сразу пишут «Киб», «МиБ», «ГиБ», чтобы не было сомнений, о чем идет речь.

Двоичные приставки в ОС Linux, OS X и в профессиональных обзорах 1 кибибайт (КиБ или KiB или kebibyte) = 1024 байт
3. Использование десятичных приставок
Если используется приставка «кило», «мега», «гига» и т.д., то имеются в виду следующие соотношения:

Десятичные приставки используют производители накопителей (Жесткие диски, флэшки, DVD-диски) 1 килобайт (кБ или kB или kbyte) = 1000 байт
Куда исчезли 70 гигабайт на жестком диске???
Посмотрим, как Windows видит два моих жестких диска 500 ГБ и 1 ТБ:

Жесткий диск 500 ГБ отображается как 465.76 ГБ, а винчестер объемом 1000 ГБ содержит всего 931.51 гигабайт.
Наверное, Вы уже догадались, почему жесткий диск объемом 1 Терабайт в ОС Windows отображается как 931 ГБ, а не 1000.
Так что, не ругайте производителей и уж тем более компьютерную фирму, всё отмерено верно, но разными рулетками
Т.е. 70 гигабайт никуда не делись, просто гибибайт на жестком диске меньше, чем гигабайт.
Не запутались? Тогда еще один пример.
«Почему на флешке меньше места?»
То же самое и с флэш-накопителями. Если Вы посмотрите на свойства своей флэшки, то (к примеру) вместо 16 GB, указанных на корпусе, увидите 14.9 ГБ!!!
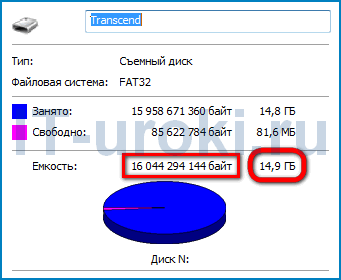
На флешке вместо 16 GB — 14.9 ГБ
Теперь Вы знаете, что 1.1 ГБ «потерялся» при пересчете из килобайт в кибибайты.
Бит и байт — минимальные единицы измерения информации
Мы уже знаем, что компьютер воспринимает всю информацию через нули и единички.
Бит – это минимальная единица измерения информации, соответствующая одной двоичной цифре («0» или «1»).
Бит — это только 0 («ноль») или только 1 («единичка»). С помощью одного бита можно записать два состояния: 0 (ноль) или 1 (один). Бит — это минимальная ячейка памяти, меньше не бывает. В этой ячейке может храниться либо нолик, либо единичка.
Байт состоит из восьми бит. Используя один байт, можно закодировать один символ из 256 возможных (256 = 28). Таким образом, один байт равен одному символу, то есть 8 битам:
1 символ = 8 битам = 1 байту.
Буква, цифра, знак препинания — это символы. Одна буква — один символ. Одна цифра — тоже один символ. Один знак препинания (либо точка, либо запятая, либо вопросительный знак и т.п.) — снова один символ. Один пробел также является одним символом.
Кроме бита и байта, конечно же, есть и другие, более крупные единицы измерения информации.